
省流版:如果你是小显存,装他,装他。如果想画很大很大的图,装他,装他。
开宗明义:SD是一款很强大的AI绘画软件,使用GPU进行大量运算后生成图片。但是这个算法非常吃显存,在我这篇文章中 (【AI教程】AI绘画硬件科普-显卡挑选指南), 我认为最甜的显存线是12G,且相对小的显存依旧有很大的使用困难,容易爆显存数据溢出绘画失败。
对此,pkuliyi2015(北大的大佬?)开发了MultiDiffusion with Tiled VAE这个项目,链接如下↓
https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111
该插件可以大幅减少SD运算的时候所需显存,相当于是连续画多张图,再合并起来。这种拆分任务的方式让显存较小的硬件也能够低成本地画出更大的图。
同时,由于这个特性,让MultiDiffusion with Tiled VAE甚至能够在参数不变的情况下将原图从1024 * 800 放大到 4096 * 3200。
安装方法
点开SD webui的最右边的选项卡:拓展
在下面这个“已安装”右边找到“可用”,寻找【MultiDiffusion with Tiled VAE】安装即可
功能介绍
以下内容部分全部引用来自该项目的中文说明:https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111/blob/main/README_CN.md
功能
🆕 Tiled Noise Inversion
- 超高分辨率高质量图像放大,8k图仅需12G显存
- 尤其适用于人像放大,当你不想大幅改变人脸时
- 4x放大效果,去噪强度0.4
🔥 Tiled VAE
- 几乎无成本的降低显存使用。
- 您可能不再需要 --lowvram 或 --medvram。
- 以 highres.fix 为例,如果您之前只能进行 1.5 倍的放大,则现在可以使用 2.0 倍的放大。
- 通常您可以使用默认设置而无需更改它们。
- 但是如果您看到 CUDA 内存不足错误,请相对降低两项 tile 大小。
区域提示控制
通过融合多个区域进行大型图像绘制。
注意:我们建议您使用自定义区域来填充整个画布。
以高分辨率绘制多个角色
- 参数:
- 模型:Anything V4.5, 高度 = 1920, 宽度 = 1280 (未使用highres.fix), 方法(Method) = Mixture of Diffusers
- 全局提示语:masterpiece, best quality, highres, extremely clear 8k wallpaper, white room, sunlight
- 全局负面提示语:ng_deepnegative_v1_75t EasyNegative
- ** 块大小(tile size)参数将不起效,可以忽略它们。**、
- 区域:
- 区域 1:提示语 = sofa,类型 = Background
- 区域 2:提示语 = 1girl, gray skirt, (white sweater), (slim) waist, medium breast, long hair, black hair, looking at viewer, sitting on sofa,类型 = Foreground,羽化 = 0.2
- 区域 3:提示语 = 1girl, red silky dress, (black hair), (slim) waist, large breast, short hair, laughing, looking at viewer, sitting on sofa,类型 = Foreground,羽化 = 0.2
区域布局:

结果 (4张中的2张)


示例2:绘制全身人物
- 通常情况下,以高分辨率绘制全身人物会比较困难(例如可能会将两个身体连接在一起)。
- 通过将你的角色置入背景中,可以轻松的做到这一点。
- 参数:
- 模型:Anything V4.5,宽度 = 1280,高度 = 1600 (未使用highres.fix),方法(Method) = MultiDiffusion
- 全局提示语:masterpiece, best quality, highres, extremely clear 8k wallpaper, beach, sea, forest
- 全局负面提示语:ng_deepnegative_v1_75t EasyNegative
- 区域:
- 区域 1:提示语 = 1girl, black bikini, (white hair), (slim) waist, giant breast, long hair,类型(Type) = Foreground,羽化(Feather) = 0.2
- 区域 2:提示语 = (空),类型(Type) = Background
- 区域布局:
- 结果: NVIDIA V100 使用 4729 MB 显存用了 32 秒生成完毕。我很幸运的一次就得到了这个结果,没有进行任何挑选。

图生图放大功能
- 利用 Tiled Diffusion 来放大或重绘图像
示例:从1024 * 800 放大到 4096 * 3200 ,使用默认参数
- 参数:
- 降噪 = 0.4,步数 = 20,采样器 = Euler a,放大器 = RealESRGAN++,负面提示语=EasyNegative,
- 模型:Gf-style2 (4GB 版本), 提示词相关性(CFG Scale) = 14, Clip 跳过层(Clip Skip) = 2
- 方法(Method) = MultiDiffusion, 分块批处理规模(tile batch size) = 8, 分块高度(tile size height) = 96, 分块宽度(tile size width) = 96, 分块重叠(overlap) = 32
- 全局提示语 = masterpiece, best quality, highres, extremely detailed 8k wallpaper, very clear, 全局负面提示语 = EasyNegative.
-
- 放大前:

4倍放大后: 无精选,在 NVIDIA Tesla V100 上使用1分12秒生成完毕(如果只放大2倍,10秒即可生成完毕)

使用方法
Tiled VAE
- 在第一次使用时,脚本会为您推荐设置。
- 因此,通常情况下,您不需要更改默认参数。
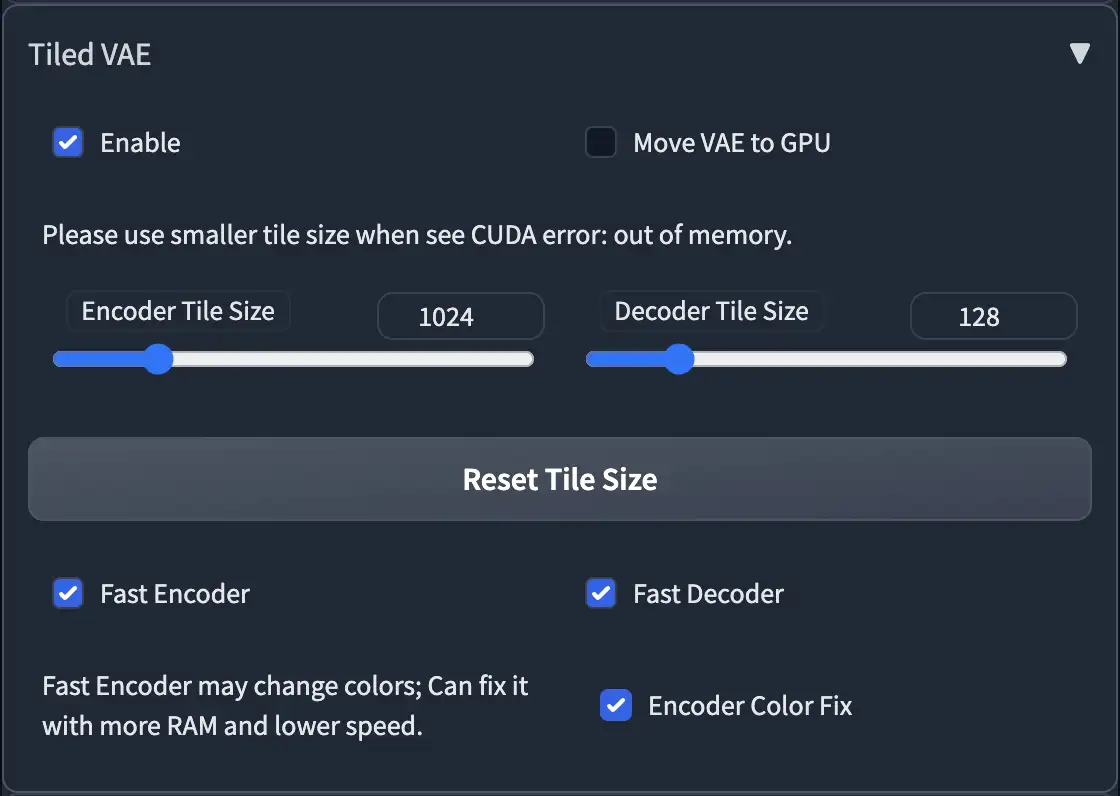
- 只有在以下情况下才需要更改参数:
- 爆显存的时候,降低 tile 大小,也可以勾选MOVE VAE to GPU
- 当您使用的 tile 太小且图片变得灰暗和不清晰时,请启用编码器颜色修复。
Tiled Diffusion
- 主选项 / 图像分块选项
下图所示部分控制图像的分块参数:
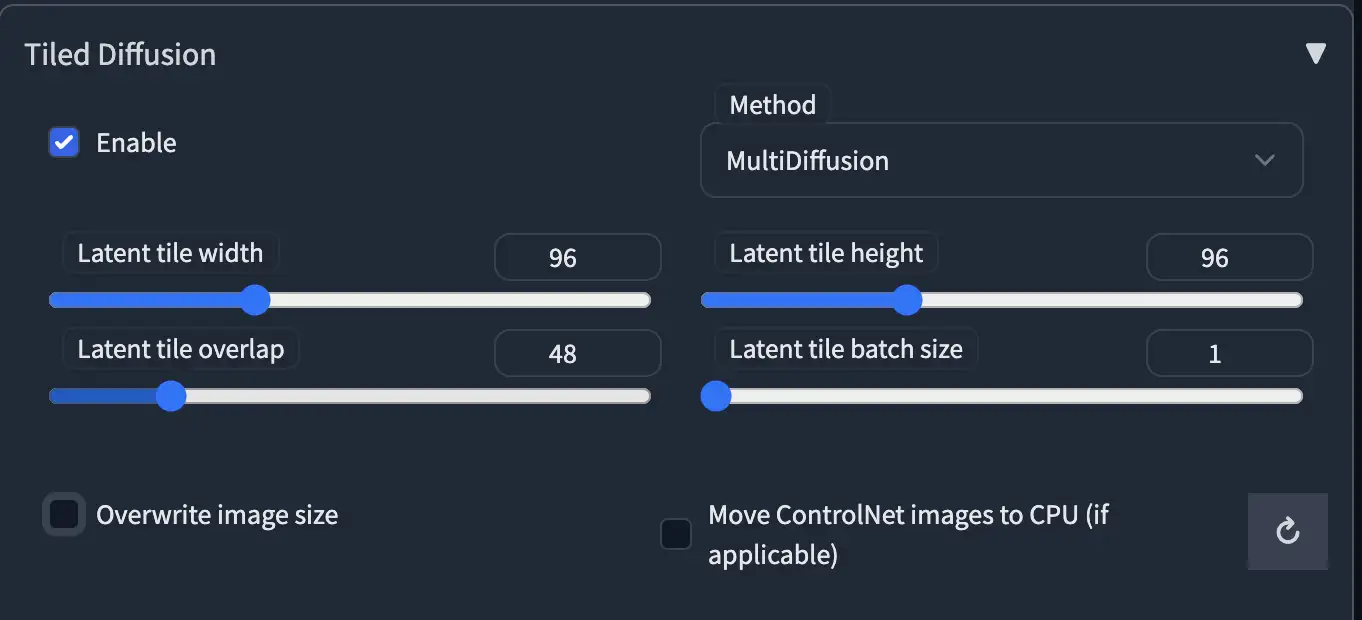
这里是一个示例图:
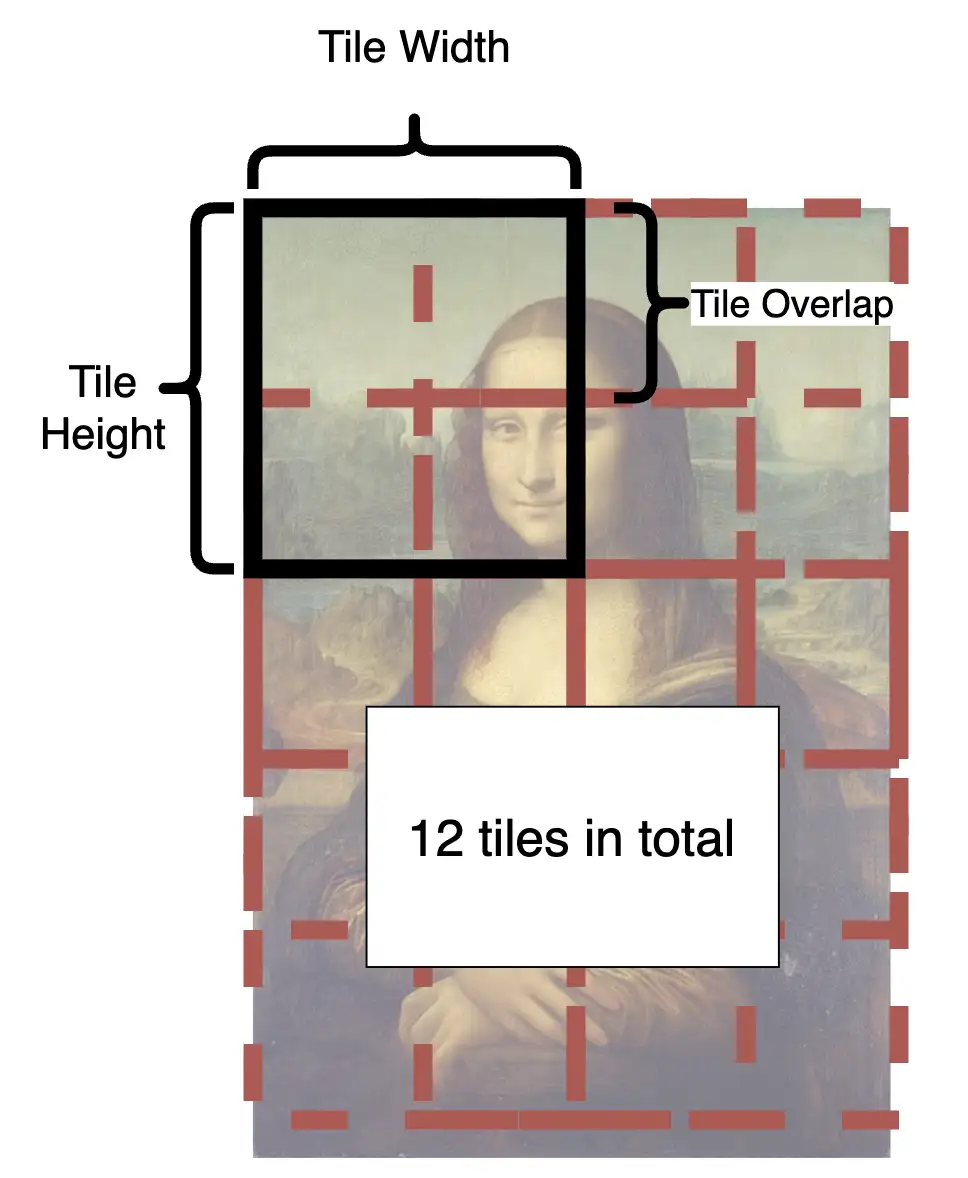
- 从图中可以看到如何将图像分割成块。
- 在每个步骤中,潜在空间中的每个小块都将被发送到 Stable Diffusion UNet。
- 小块一遍遍地分割和融合,直到完成所有步骤。
- 块要多大才合适?
- 较大的块大小将提升处理速度,因为小块数量会较少。
- 然而,最佳大小取决于您的模型。SD1.4仅适用于绘制512 * 512图像(SD2.1是768 * 768)。由于大多数模型无法生成大于1280 * 1280的好图片。因此,在潜在空间中将其除以8后,你将得到64-160。
- 因此,您应该选择64-160之间的值。
- 个人建议选择96或128以获得更快的速度。
- 重叠要多大才合适?
- 重叠减少了融合中的接缝。显然,较大的重叠值意味着更少接缝,但会显著降低速度,因为需要重新绘制更多的小块。
- 与 MultiDiffusion 相比,Mixture of Diffusers 需要较少的重叠,因为它使用高斯平滑(因此可以更快)。
- 个人建议使用 MultiDiffusion 时选择32或48,使用 Mixture of Diffusers 选择16或32
- 放大算法(Upscaler) 选项将在图生图(img2img)模式中可用,你可选用一个合适的前置放大器。
区域提示语控制
- 通常情况下,所有小块共享相同的主提示语。
- 因此,您不能使用主提示语绘制有意义的对象,它会在整个图像上绘制您的对象并破坏您的图像。
- 为了处理这个问题,我们提供了强大的区域提示语控制工具。
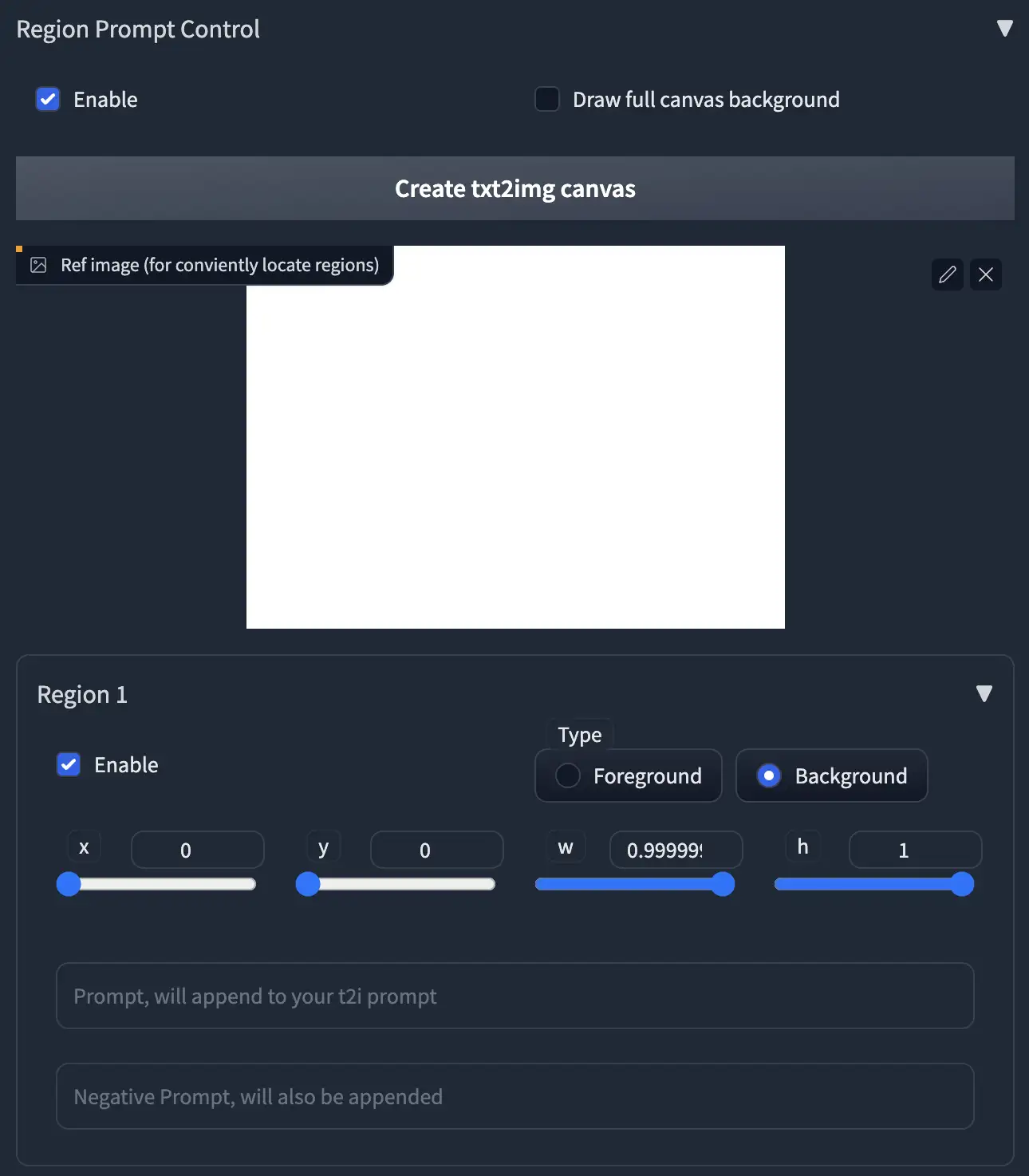
- 首先,启用区域提示语控制。
- 注意:启用区域控制时,默认的小块分割功能将被禁用。
- 如果您的自定义区域不能填满整个画布,它将在这些未覆盖的区域中产生棕色(MultiDiffusion)或噪声(Mixture of Diffusers)。
- 我们建议您使用自己的区域来填充整个画布,因为在生成时速度可能会更快。
- 如果您懒得绘制,您也可以启用绘制完整的画布背景。但是,这将显著降低生成速度。
2.上传一张图片,或点击按钮创建空白图像作为参考。
3.点击区域1的启用,您将在图像中看到一个红色的矩形。
-
- 在区域中点击并拖动鼠标以移动和调整区域大小。
4.选择区域类型。如果您想绘制对象,请选择前景。否则选择背景。
-
- 如果选择前景,则会出现羽化。
- 较大的值将为您提供更平滑的边缘。
5.输入区域的提示语和负面提示语。
-
- 注意:您的提示将附加到页面顶部的主提示语中。
- 您可以利用此功能来节省你的词条,例如在页面顶部使用使用常见的提示语(如“masterpiece, best quality, highres...”)并使用“EasyNegative”之类的 embedding 。
- 您也可以在提示语中使用 Textual Inversion 和 LoRA
提高分辨率的特别提示
- 提高分辨率的推荐参数
- 采样器(Sampler) = Euler a,步数(steps) = 20,去噪强度(denoise) = 0.35,方法(method) = Mixture of Diffusers,潜变量块高和宽(Latent tile height & width) = 128,重叠(overlap) = 16,分块批处理规模(tile batch size)= 8(如果 CUDA 内存不足,请减小块批量大小)。
- 支持蒙版局部重绘(mask inpaint)
- 如果你想保留某些部分,或者 Tiled Diffusion 给出的结果很奇怪,只需对这些区域进行蒙版。
- 所用的模型很重要
- MultiDiffusion 与 highres.fix 的工作方式非常相似,因此结果非常取决于你所用的模型。
- 一个能够绘制细节的模型可以为你的图像添加惊人的细节。
- 使用完整的模型而不是剪枝版(pruned)模型可以产生更好的结果。
- 不要在主提示语中包含任何具体对象,否则结果会很糟糕。
- 只需使用像“highres, masterpiece, best quality, ultra-detailed 8k wallpaper, extremely clear”之类的词语。
- 如果你喜欢,可以使用区域提示语控制来控制具体对象。
- 不需要使用太大的块大小、过多的重叠和过多的降噪步骤,否则速度会非常慢。
- 提示词相关性(CFG scale)可以显著影响细节
- 较大的提示词相关性(例如 14)可以提供更多的细节。
- 你可以通过0.1 - 0.6 的降噪强度来控制你想要多大程度地改变原始图像.
- 如果你的结果仍然不如我的满意,可以在这里查看我们的讨论。
技术部分
这部分内容是给想知道工作原理的人看的。
Tiled VAE
核心技术是估算 GroupNorm 参数以实现无缝生成。
- 图像被分成小块,然后在编码器 / 解码器中各进行了 11/32 像素的扩张。
- 当禁用快速模式时:
- 原始的 VAE 前向传播被分解为任务队列和任务工作器,开始处理每个小块。
- 当需要 GroupNorm 时,它会暂停,存储当前的 GroupNorm 均值和方差,将所有内容发送到内存中,然后转到下一个小块。
- 在汇总所有 GroupNorm 均值和方差之后,将结果应用到小块中并继续。
- 使用锯齿形执行顺序以减少不必要的数据传输。
- 当启用快速模式时:
- 原始输入被下采样并传递到单独的任务队列。
- 它的 GroupNorm 参数被记录并由所有小块的任务队列使用。
- 每个小块被单独处理,没有任何 内存 <-> 显存 的数据传输。
- 处理完所有小块后,小块被写入结果缓冲区并返回。
编码器颜色修复 = 仅在下采样之前估计 GroupNorm,即以半快速模式运行。
Tiled Diffusion
- 潜在图像被分成小块。
- 在 MultiDiffusion 中:
- UNet 预测每个小块的噪声。
- 小块由原始采样器去噪一个时间步。
- 小块被加在一起,但除以每个像素的累加次数(即加权平均)。
- 在 Mixture of Diffusers 中:
- UNet 预测每个小块的噪声。
- 所有噪声与高斯权重蒙版融合。
- 降噪器对整个图像使用融合的噪声去噪一个时间步。
- 重复执行步骤 2-3,直到完成所有时间步长。
优点
- 在有限的显存中绘制超大分辨率(2k~8k)图像
- 无需任何后处理即可实现无缝输出
缺点
- 它将明显比通常的生成速度慢。
- 梯度计算与此技巧不兼容。它将破坏任何 backward() 或 torch.autograd.grad()。
转载请注明:【转载】Stable Difussion显存不够用的解决方法 MultiDiffusion with Tiled VAE插件分享 | AI应用导航网
相关文章
